

Why Data Overload Happens and Why It Is a Problem for Cybersecurity Teams


The following is an excerpt from our recently published whitepaper, “The Data Overload Problem in Cybersecurity.” In this whitepaper, we dive into the data overload problem plaguing the cybersecurity industry and uncover how organizations can greatly reduce or even completely eliminate many of these challenges by adopting an AI-driven solution to analyze network behavior in the context of current data while meeting compliance and regulatory requirements.
Why Data Overload Happens and Why It Is a Problem
Handling and managing data today has become unwieldy for IT teams on multiple fronts, but the security impact is especially troubling.
Not only is data at risk of becoming effectively valueless because it is inaccessible, but on the flip side the process and tool based inefficiencies causing data overload have made data more vulnerable to bad actors.
Security platforms are not typically developed to address the true nature of today’s networking and storage realities.
For security teams, the crux of the problem lies in dealing with a massive amount of data that must be stored, aggregated and managed in order to extract the information needed to detect threats.
Recently Roger Grimes from InfoWorld explained how this very problem affects cybersecurity teams:
“We get information overload from everywhere. Companies simply do not have the time to analyze every single drop from the information ocean that they get daily. The ‘manual’ approach to log file analysis is just not an option…most alerting systems are 99.999 percent full of events that indicate nothing malicious whatsoever.”
Oftentimes, as this chart from McAfee shows, security operations teams simply ignore the alerts because there is just too much data to deal with.
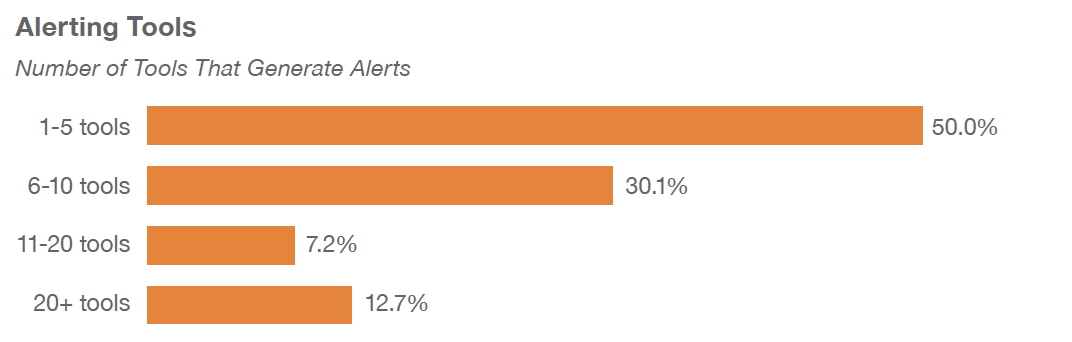
Enterprises are forced to sift through the same data over and over again to find and understand the details. This means securing this data adequately causes a massive burden both financially and in terms of human work for enterprises. Most enterprises are utilizing an inefficient, outdated approach that does not deliver the desired goal of accessibility and security.
In many ways, vendors are making the “data overload” problem worse for security teams.
Organizations that continue to deploy and rely on information security solutions entirely based on historical data stores are applying a legacy approach to a modern issue and falling short when it comes to data privacy and regulatory compliance.
A fresh approach to data management is more than overdue. Solutions that employ a new type of artificial intelligence called self-supervised AI, which does not require constant human supervision, can fundamentally shift the way enterprises access, retain and retrieve their data away from the typical historical approach to one that focuses on real-time data, which can fundamentally improve the company’s security posture.
Click here to continue reading, “The Data Overload Problem in Cybersecurity.”
MixMode Articles You Might Like:
Why SIEM Has Failed the Cybersecurity Industry
Data Overload Problem: Data Normalization Strategies Are Expensive
What is Predictive AI and How is it Being Used in Cybersecurity?
Whitepaper: The Data Overload Problem in Cybersecurity
Magnify Podcast: Discussing the New Normal with AI Based Cybersecurity Specialists, MixMode
MixMode Platform Update: Support for Google Cloud
Phishing for Bitcoin: The Twitter Hack Masterminded by a 17 Year Old